| Version 1 (modified by , 9 years ago) (diff) |
|---|
The Basics:
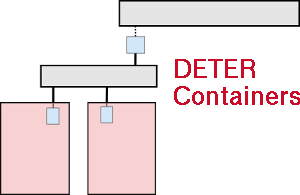
The neo-containers system uses cloud-container technology to abstract and generalize container creation and initialization. There is a per-experiment control node that centralizes configuration details. At the DETER level, the experiments have the control node and a number of "pnodes" which serve as hosts for the virtualized containers. The control node configures the pnodes as well as the containerized nodes as well as itself. The bootstrap script is run on the control node and: 1) installs configuration software on itself, 2) updates its own configuration, 3) updates the configuration of the other physical nodes (which includes virtual networking and starting virtual machines), 4) give configuration information to virtual nodes and allows them to configuration themselves.
Execution Flow:
The execution flow of is as follows. The initialization uses the existing containers system as a bootstrap.
- Create a containerized experiment with an NS file and the
/share/containers/containerize.pyscript. - Modify the generated NS file.
- Change the OS type of the pnodes to
PNODE-BASE. e.g. make the line in the NS file:tb-set-node-os ${pnode(0000)} PNODE-BASE - Add a new control node. Traditionally it's been called "config", but there is no restriction on the name. Add this to the NS file:
set config [$ns node] tb-set-node-os ${config} Ubuntu1404-64-STD tb-set-hardware ${config} MicroCloud tb-set-node-failure-action ${config} "nonfatal"
- Change the OS type of the pnodes to
- Swap in the experiment.
- Run the bootstrap script.
The bootstrap script:
- Uses the NFS mounted dir /share/chef/chef-packages to install Chef server and Chef client on the
confignode.- The
confignode is both a Chef server (talks to all machines in the experiment) and a Chef client/workstation (holds the Chef git repo which contains all configuration scripts).
- The
- Configures Chef Server on the
confignode.- Simply runs the chef self-configure scripts.
- Configures Chef client/workstation on the
confignode.- creates a chef-deter identity (keys and names) for the Chef Server.
- installs
giton theconfignode. - git clones the canonical Chef repository from the NFS mounted dir
/share/chef/chef-repo. Thie repo contains all configuration scripts and data for the system. - upload all Chef recipes, data bags, and roles (configuration scripts, data, and roles) to the Chef server on
config(localhost).
- Create an experiment-specific "data bag" and upload it to the Chef Server. The data contains experiment name, project, group, name and address of the
configmachine, and the name and address of the RESTful configuration server. - Register the
confignode (localhost) as a Chef client to the server, download and execute all local configuration recipes. Details of these are in the next section.
config recipes.